Treasury Pay | Sr. Data Engineer | 2018-2020
About Link to heading
My fist significant contract project was a financial platform for global retailers with Invictus Gurus, a consultancy based in Dallas, Tx.
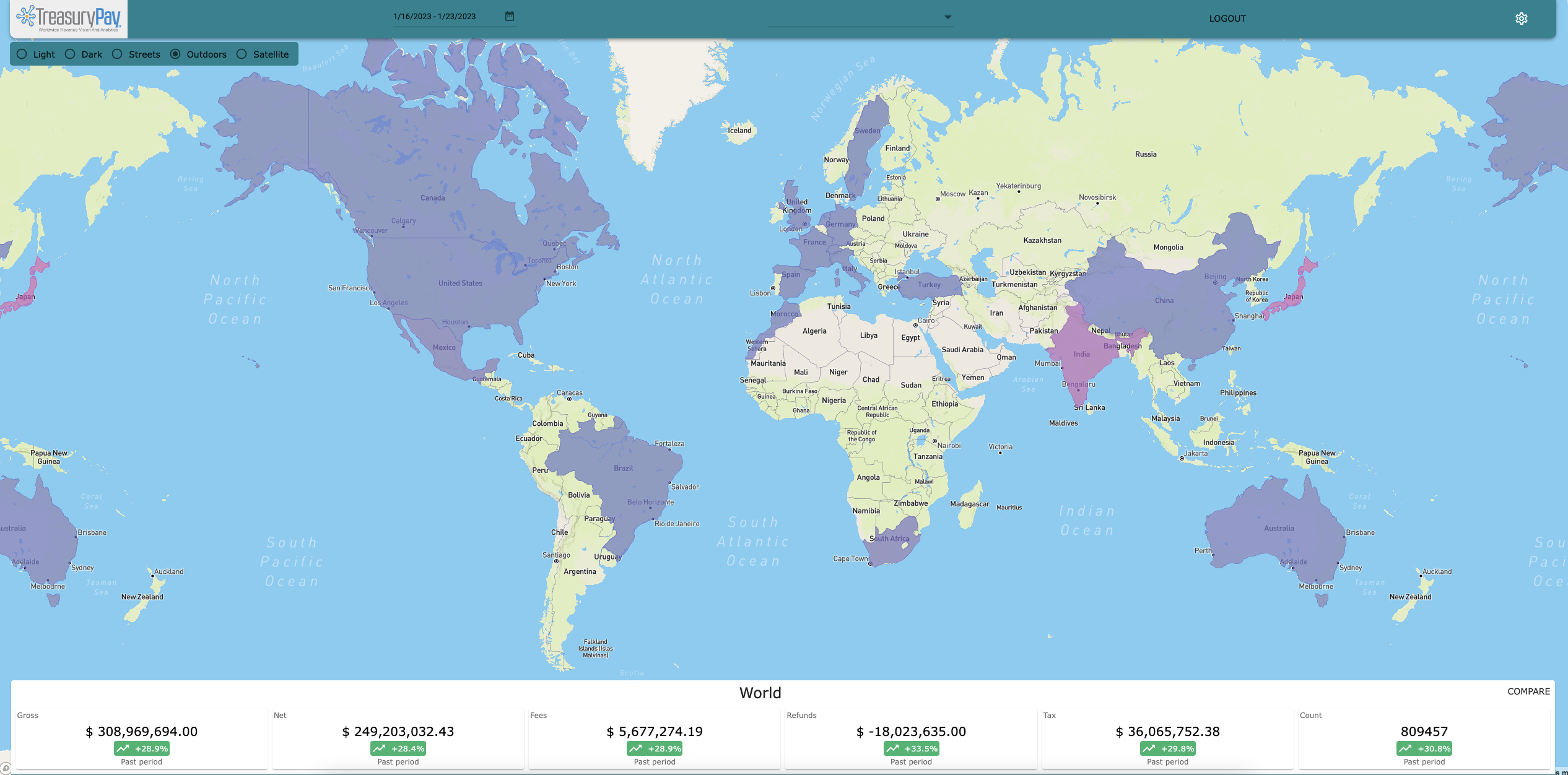
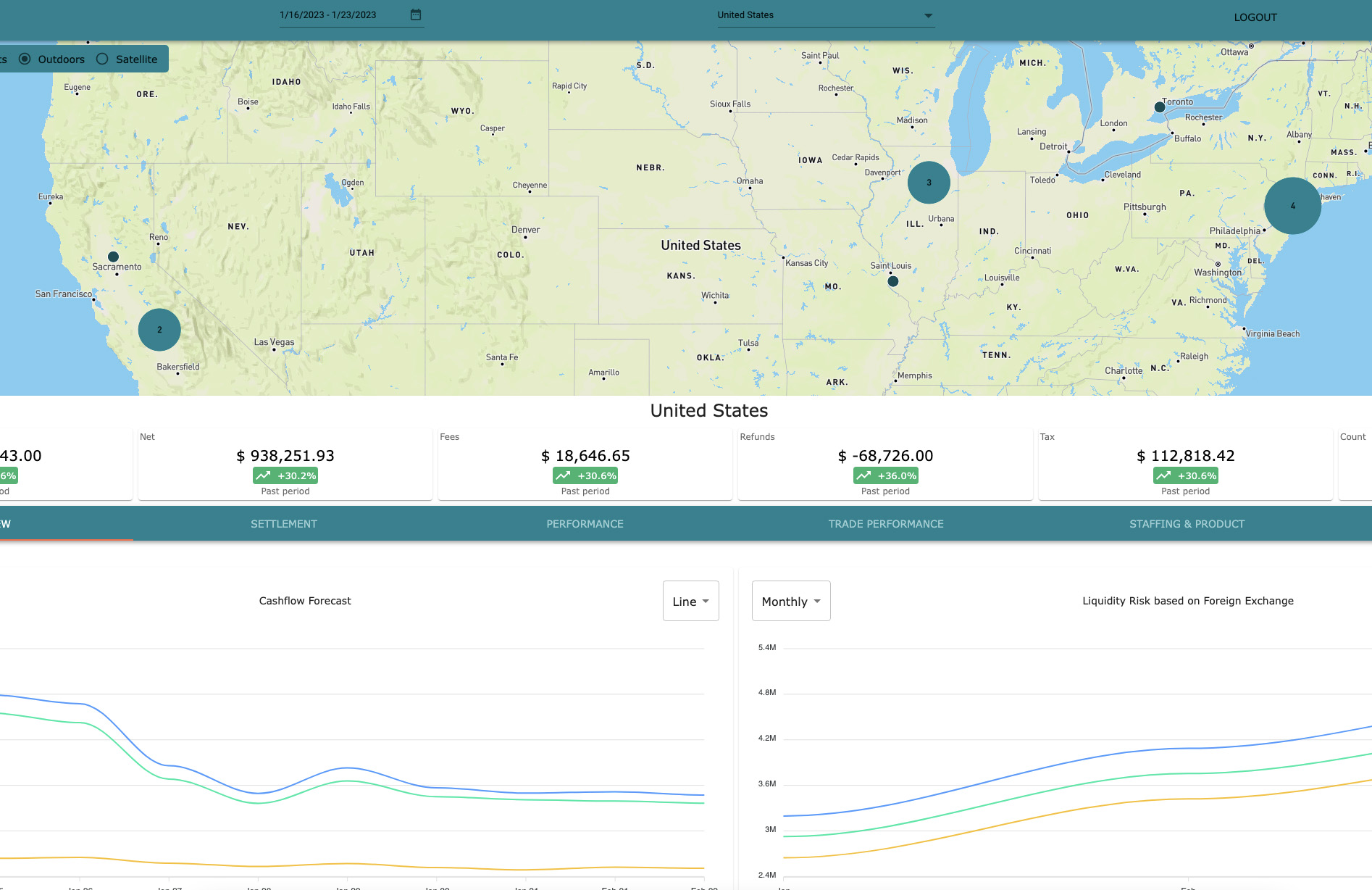
The software manages high throughput point-of-sale transactions and offers companies with a global retail footprint the opportunity to get highly granular metrics on their banking, revenue and forecasting data.
I was initially engaged to bring the proof of concept application back online after some unexpected downtime. I lead the technical architecture and implementaiton of the big data components for the production phase that followed. I settled on a series of open source big data technologies, tied together with distributed infrastructure on Kubernetes.
I had worked with most of the technologies in the final stack, but this was my first experience tying together so many tools together in a high volume - production context. Standing up this data stack was thrilling in many ways and very satisfying to see my design ideas work at scale and meet the client requirements.
Impact Link to heading
- Led big data architecture and implementation of a high throughput financial platform, supporting 100k+ transactions per second
- Wrote complex data manipulation pipelines in Spark & Spark Streaming.
- Built out base Elasticsearch data caching layer for low latency frontend consumption via API.
- Built out distributed, platform agnostic infrastructure on Kubernetes
Technology
Data Architecture Context
- High throughput - system needed to support hundreds of thousands of transactions per second
- Linear scaling - system needed to scale linearly with data volume
- Processing load - system required complex and compute heavy data processing
- Low latency - system needed to supply high volume of processed and formated data to the front-end
- Flexibility - ingesting and building new datasets on a per-client basis
- Geo + temporal domains - Incoming data was primarily time-series and segmented on location, so the system needed to focus on these dimensions for search and scoping.
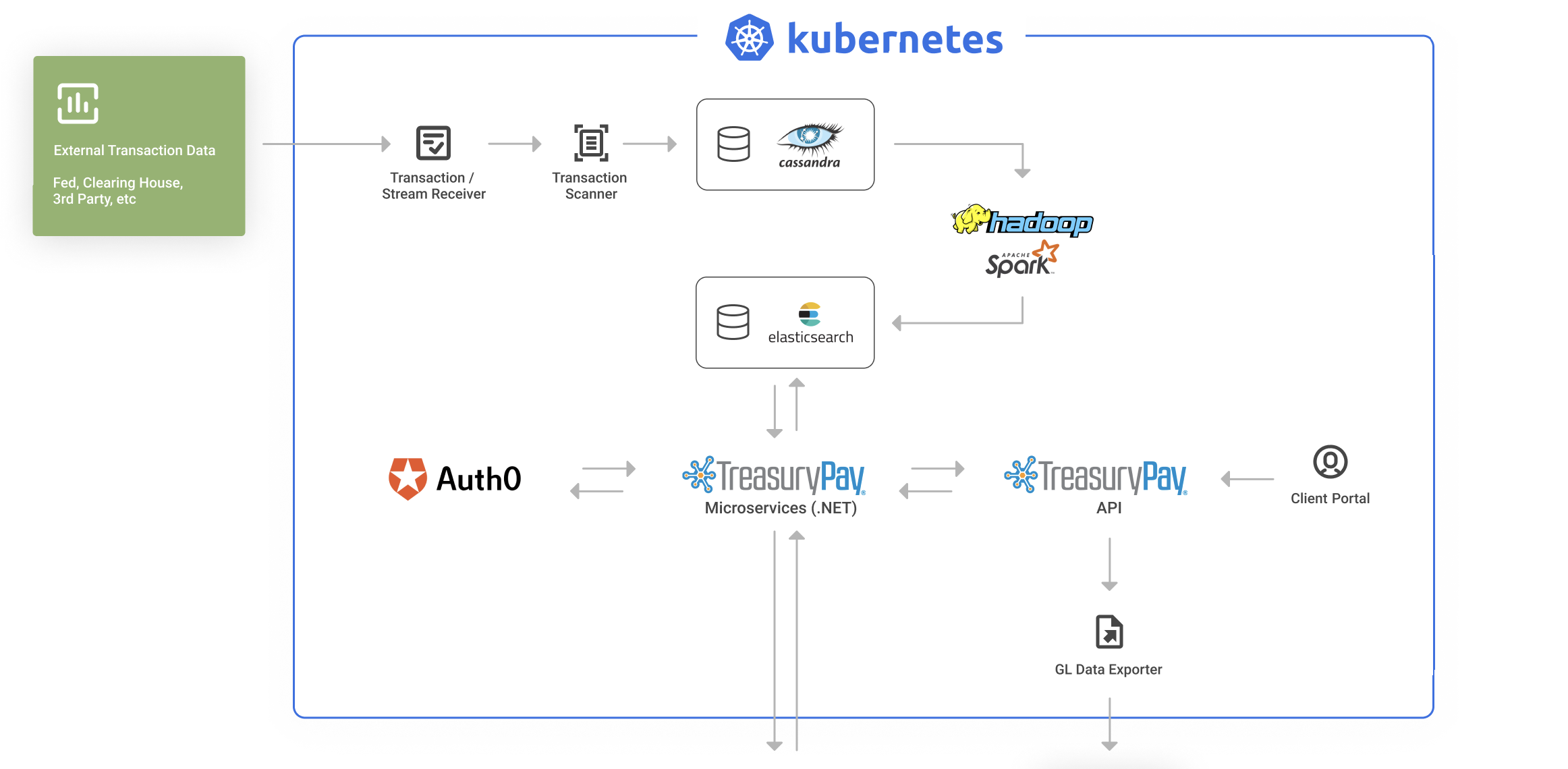
Data Architecture Delivery
- Data Firehose - socket based data streamer written in python - to benchmark data volumes
- Spark Streaming - handling ingest and initial processing of raw external data
- Cassandra - wide column data warehouse to store incoming data streams, cold and long term data
- Spark Core - loading and processing datasets from cassandra into final format
- Elasticsearch - Application data caching layer for low latency consumption over API